AnySearch:让 AI 搜索更精准
AI Agent 最容易翻车的地方,往往不是写代码,而是“以为自己知道”。
一个项目刚更新过,模型还停留在旧版本;一条新闻有后续,它只记得前半段;一份文档明明在网页上,它却用训练时的印象补了一句看起来很顺的答案。人读起来没那么容易发现问题,因为语言是连贯的,错也错得很自然。
所以我现在越来越倾向于把搜索能力当成 Agent 的基础设施,而不是临时补丁。需要新资料时,它应该能明确地查、抽取、交叉验证,而不是靠上下文里残留的几段笔记硬拼。
AnySearch 这个技能解决的就是这件事:给 Agent 装上一套可复用的实时搜索入口。

查资料总靠猜:先给 Agent 一条搜索路径
如果只是让模型去搜网页,办法很多。
真正麻烦的是后面的细节:要不要查一般网页?要不要查垂直领域?多个问题能不能并行?搜索结果不够时,能不能把某个 URL 的正文抽出来?不同机器上 Python、Node、Shell 环境不一样,调用方式要不要每次重新判断?
AnySearch 把这些都收进一个 skill 里。
它支持四类常用动作:
- 普通网页搜索。
- 垂直领域搜索,比如金融、学术、代码、安全、法律、旅行等方向。
- 批量搜索,一次跑多个互不依赖的问题。
- URL 内容抽取,把网页正文转成 Markdown,方便 Agent 继续阅读和引用。
项目本身走的是 JSON-RPC 2.0 接口,技能目录里配了跨平台 CLI。也就是说,Agent 不需要你单独架 MCP server,只要技能安装好,就可以通过 Python、Node.js 或 Shell 脚本去调用同一套搜索服务。
这点很实际。很多 Agent 工作流坏在“第一次能跑,换台机器就断”。AnySearch 的做法是先检测运行环境,优先选 Python,其次 Node.js,再退到 Shell。检测结果会写进 runtime.conf,后面日常搜索直接用这条命令,不用每次重新试。
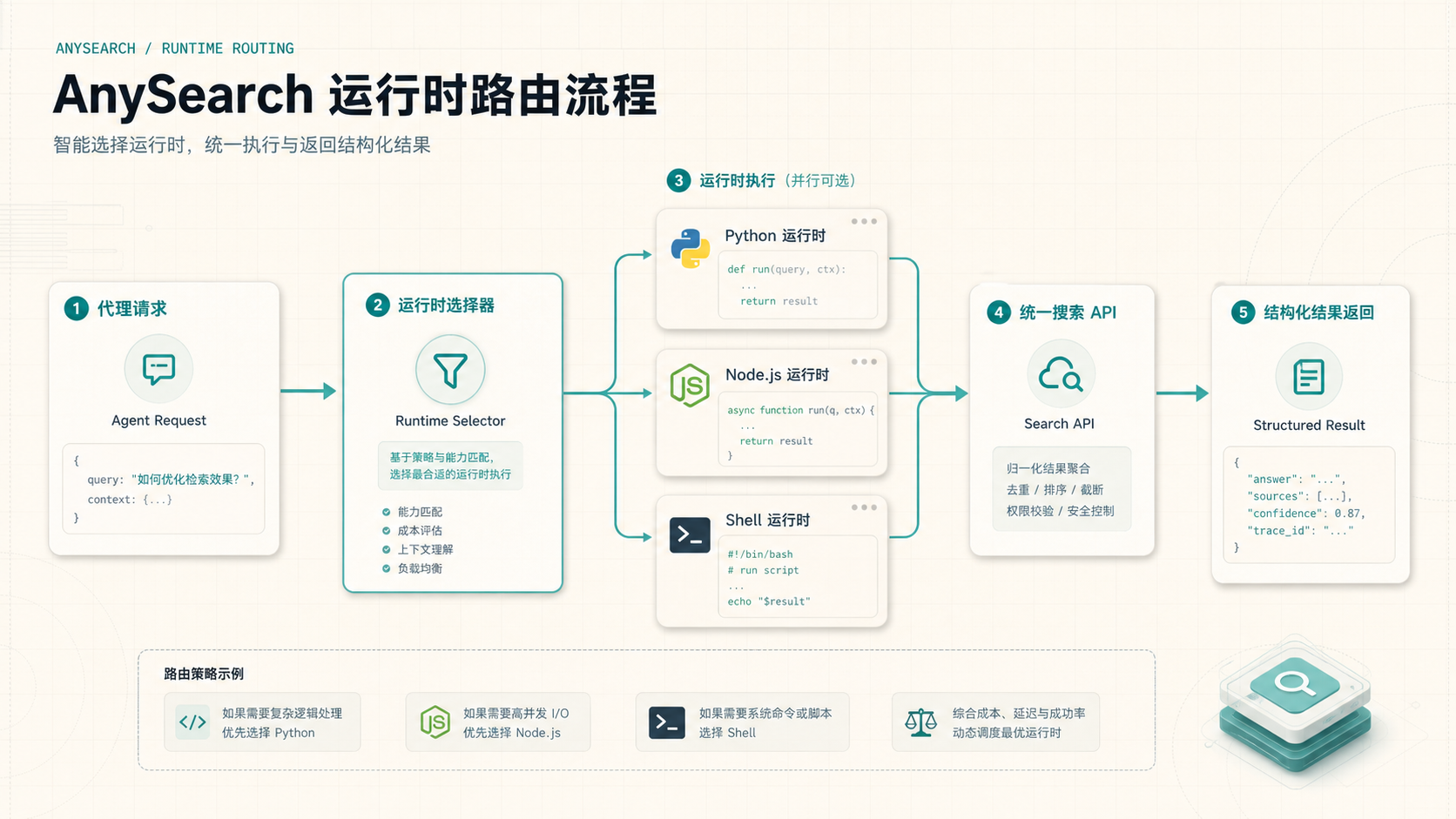
搜索结果太散:先分清普通搜索和垂直搜索
AnySearch 的技能说明里有一个挺强硬的规则:只要问题和某个垂直领域沾边,就应该先查 get_sub_domains,再按返回的 sub_domain 和必填参数去搜。
这不是文档洁癖。
普通网页搜索适合找入口和概览,但很多问题不是“网页里有没有这几个词”就能解决。股票、CVE、DOI、专利、机场代码、开源项目、法律条文,这些都有更结构化的搜索方式。直接丢给通用搜索,经常会拿到看似相关、实际很散的结果。
垂直搜索的价值是先问清楚“这个领域该怎么查”。如果返回参数里有必填项,就算暂时没有值,也要显式传空字符串。这个规则听起来啰嗦,但对 Agent 很重要:它让搜索行为更可控,也减少模型自己猜字段、猜格式的空间。
不确定该走普通搜索还是垂直搜索时,比较稳的做法是混合:用 batch_search 同时跑一个普通查询和几个垂直查询。覆盖面比一次猜中更重要。
摘要不够可信:把 URL 正文抽出来核对
很多错误不是发生在“搜不到”,而是停在了搜索摘要。
摘要能告诉你一个页面可能相关,但不能替你确认细节。AnySearch 的 extract 就是为这个阶段准备的:给它一个 URL,它会抽取网页正文,并以 Markdown 返回。对 Agent 来说,这比让模型盯着搜索结果标题继续发挥要靠谱得多。
这里也有边界。extract 主要处理 HTML 页面,不是 PDF、图片或其它复杂文件;返回内容会截断到一定长度。它适合把网页正文拉进来核对,不适合当万能爬虫。

这也解释了它和个人知识库工具的分工。
前面写过 “收藏越多越乱?用 AI 建 Wiki”,那类工具更适合长期沉淀:把网页、PDF、笔记整理成可维护的 Wiki。AnySearch 则偏向当下检索:Agent 写作、查资料、核对项目更新时,先从外部世界拿到最新证据。
一个管长期记忆,一个管实时入口。两个放在一起,Agent 才不容易一边记性很好,一边对今天发生的事毫无概念。
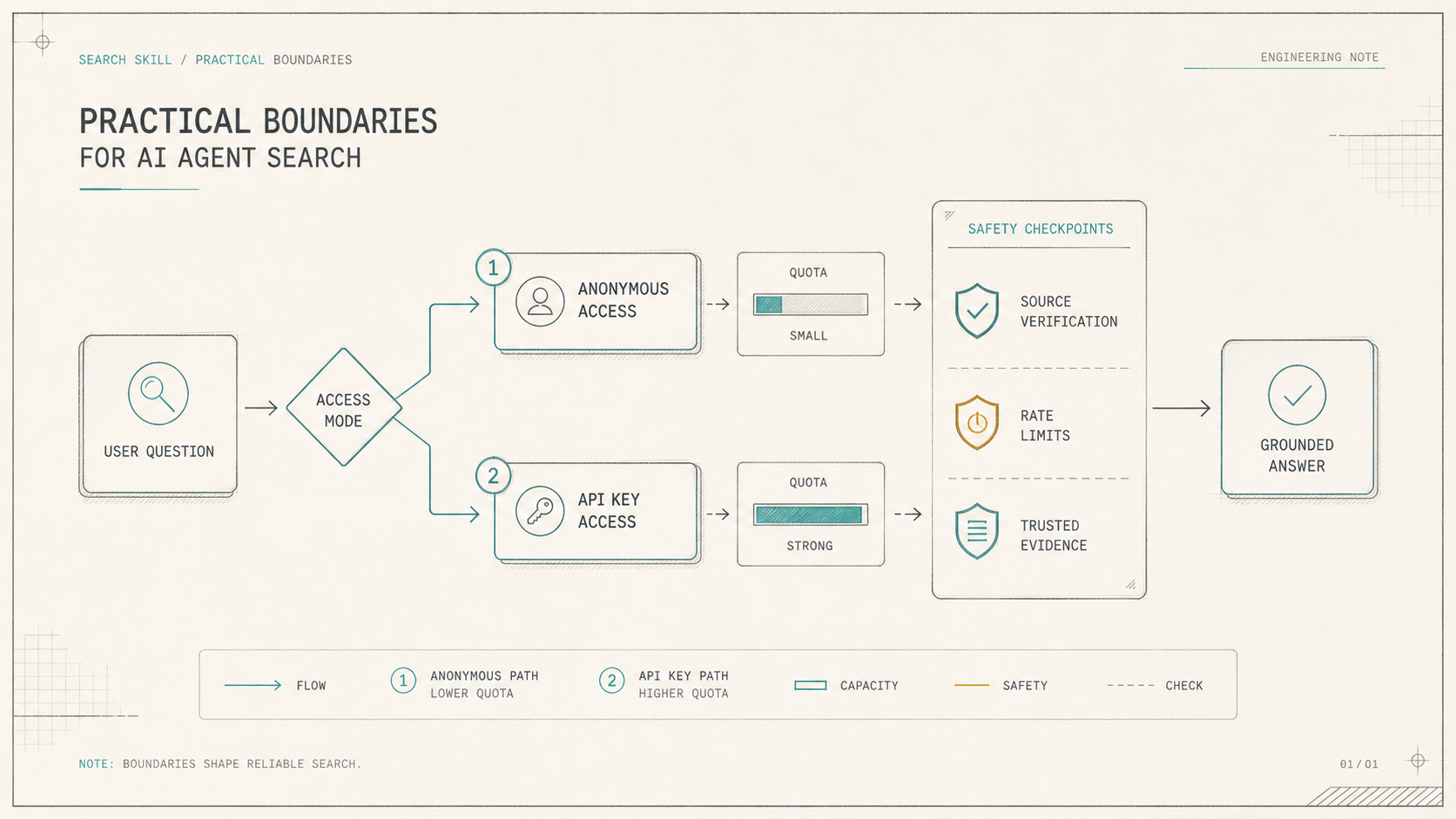
配额不稳定:API key 要放在正确位置
AnySearch 支持匿名访问,不过配额和限速会低一些。项目建议配置 API key,这个判断是合理的。
它的 key 优先级也写得很清楚:
- 命令行里的
--api_key。 - 技能目录附近的
.env。 - 环境变量
ANYSEARCH_API_KEY。 - 匿名访问。
日常使用更建议放在 .env 或环境变量里,不要把 key 写进代码,也不要在聊天里贴给 Agent。项目的安全说明也明确提到,.env 应该留在本地,并定期轮换 key。
如果匿名调用额度耗尽,服务有时会返回一个自动注册的新 key。技能规则要求 Agent 先征得用户确认,再写入 .env。这条规则有必要:key 是凭证,不应该因为一次自动化任务就悄悄落盘。
接入别太急:先跑三个小测试
一个稳妥的试法是先别急着接进复杂 Agent 流程。
先安装技能,确认本机 Python 或 Node.js 可用。然后让它跑一次环境检测,生成 runtime.conf。再做三个小测试:
- 用普通
search查一个明确项目名。 - 用
batch_search同时查两个独立问题。 - 找一个 HTML 文档页,用
extract拉正文。
如果你要查金融、学术、安全、法律、代码这类问题,先跑 get_sub_domains,看它给出的子领域和参数。别上来就把所有问题都当普通网页搜索。
也别把它理解成“搜索结果自动等于事实”。AnySearch 能把 Agent 带到资料面前,但判断资料是否可靠、是否过期、是否互相矛盾,仍然要靠后续核对。尤其是医疗、法律、财务、投资这类高风险内容,搜索只是第一步。
工作流怎么放:查新资料,沉淀旧知识
我会把它放在三种位置。
第一种是写作前的资料核对。主题、项目版本、官方文档、发布日期,都先查一遍,别用旧记忆起稿。
第二种是 Agent 编程时的文档查询。很多库更新很快,模型记住的 API 可能已经不准。先搜官方文档,再抽取具体页面,比直接让模型猜参数稳。
第三种是多来源对照。比如一个项目同时有 GitHub、官网文档和博客介绍,用批量搜索先拿入口,再逐个抽取关键页面。这样 Agent 的答案至少能站在真实材料上。
AnySearch 吸引我的地方不在“它能搜索”,而在它把搜索这件事整理成了 Agent 可以遵守的流程:什么时候查普通网页,什么时候查垂直领域,什么时候抽正文,什么时候该保存运行时配置,什么时候该提醒用户配 key。
Agent 越能干,越需要这种约束。