收藏越多越乱?用 AI 建 Wiki
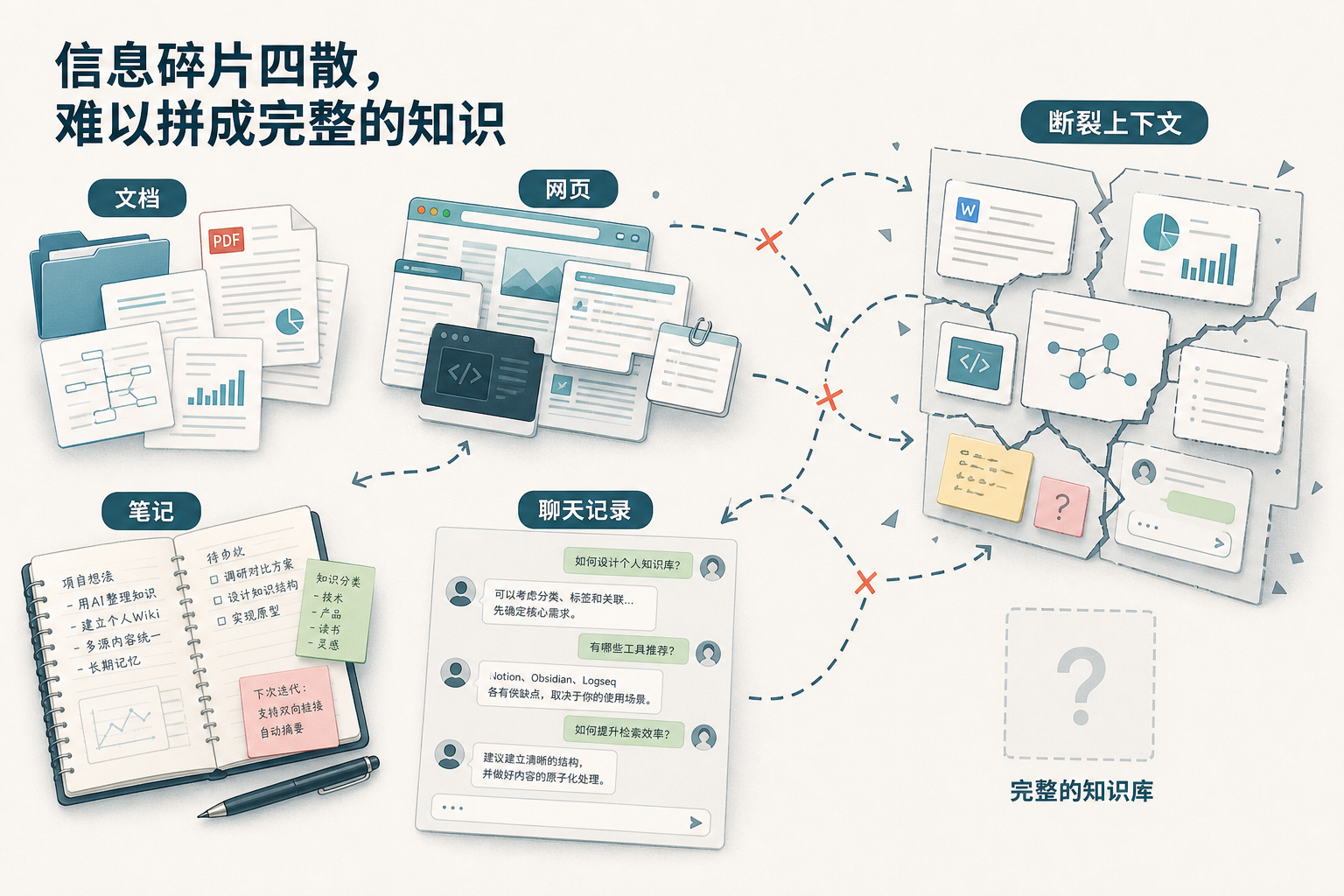
收藏夹、PDF、网页剪藏、聊天记录、读书笔记,堆到最后经常会变成另一种丢失。
东西都在,但想用的时候找不到。找到了,又要重新判断这段资料和之前的结论有没有冲突。AI 能帮忙总结一篇文章,却很难替你维护一套长期知识库。
这就是 LLM Wiki 这个思路吸引人的地方:别再把资料一次次丢给 AI 临时回答,而是先把资料变成一套持续更新的 Wiki。
Karpathy 的原始想法
Karpathy 那篇 llm-wiki 不是一个具体软件,更像一份可以丢给 Agent 的设计说明。
它抓住的问题很准:大多数 RAG 或文件问答工具,都是在提问时临时从原始资料里找片段,再拼出答案。这样当然能用,但每次提问都像从零开始。需要综合五份资料的问题,模型下次还要重新检索、重新拼接、重新推理。
LLM Wiki 的做法反过来。
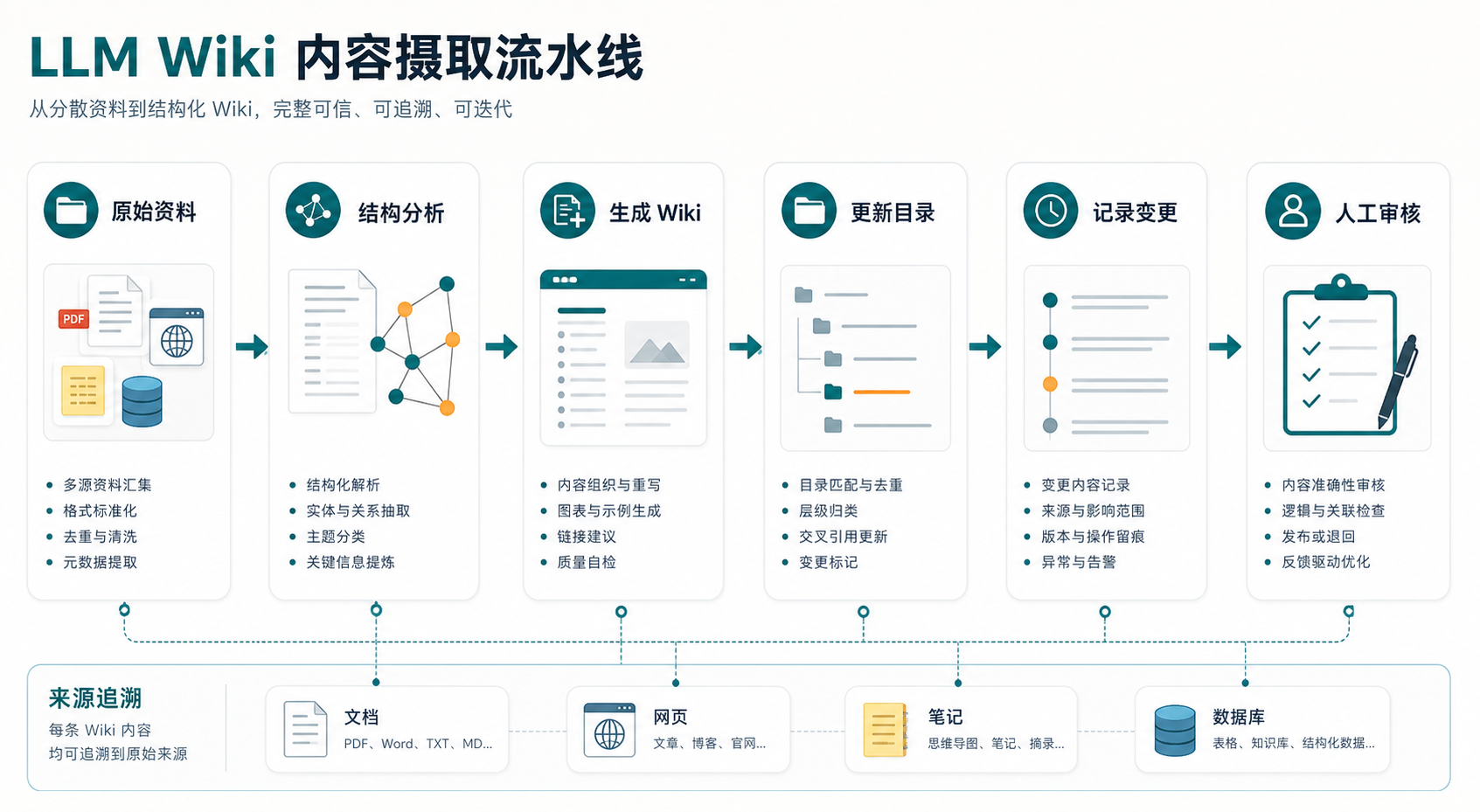
原始资料不直接拿来临时问答,而是先由 LLM 增量整理成一套 Markdown Wiki。每来一份新资料,它不只是被索引,还会进入已有结构:更新实体页、概念页、摘要页、交叉引用、矛盾记录和日志。
Karpathy 把它拆成三层:
raw sources:原始资料,是事实来源,不让 LLM 随便改。wiki:LLM 生成和维护的 Markdown 页面。schema:告诉 LLM 怎么写、怎么更新、怎么查询的规则文件。
再配三类操作:ingest 导入资料,query 基于 Wiki 提问,lint 定期检查矛盾、孤立页面、过时结论和缺失链接。
这个想法最妙的一句是:Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。
也就是说,知识库不再只是“存东西的地方”,而是一个可以被持续维护的工程。
nashsu/llm_wiki 做了什么
nashsu/llm_wiki 的价值,是把这套抽象模式做成了一个跨平台桌面应用。
Karpathy 原文更适合会折腾的人:自己建目录,写 schema,开着 Agent 和 Obsidian 一起维护。这个项目则把很多步骤包进界面和流程里,让“个人 Wiki 工程”更接近普通工具,而不是纯手工工作流。
它保留了核心架构:原始资料、Wiki、规则配置、index.md、log.md、[[wikilink]]、YAML front matter、Obsidian 兼容。
同时加了一批对真实使用很关键的东西:
purpose.md:说明这个知识库为什么存在、研究范围是什么、关键问题是什么。- 两步 ingest:先分析资料,再生成 Wiki 页面。
- 来源追溯:生成页面保留
sources[],方便回到原始资料核对。 - 持久化处理队列:导入任务可恢复、可重试、可取消。
- 文件夹导入和 source folder auto-watch:外部新增、修改、删除资料时能同步处理。
- Review 系统:把需要人判断的内容单独拎出来。
- 图谱、社区发现和 graph insights:不仅能搜,还能看关系和知识空白。
这些优化的重点不是“功能变多”,而是把维护成本往下压。
个人知识库最怕中途断掉。刚开始有热情,什么都愿意整理;过一阵子,目录更新、交叉引用、来源标注、旧结论修正,全都变成负担。LLM Wiki 把这些繁琐动作交给模型,但把审核和方向留给人。
这个分工比全自动更靠谱。
便利性在哪里
第一是入口更低。
原始模式需要你会安排目录、会写 Agent 规则、会盯着 LLM 改 Markdown。nashsu/llm_wiki 给的是桌面应用:左侧知识树和文件树,中间聊天,右侧预览。Sources、Search、Graph、Lint、Review、Deep Research、Settings 都有独立入口。
第二是资料类型更多。
项目支持 PDF、DOCX、PPTX、表格、图片、网页剪藏等多种资料。对普通个人知识库来说,这比“只支持 Markdown”重要很多。真实收藏从来不整齐,网页、PDF、会议材料、表格经常混在一起。
第三是检索不只靠向量。
它有关键词检索、可选向量检索、图谱扩展和上下文预算控制。向量搜索可以启用 LanceDB,也可以不用。这个取舍挺好:小知识库先靠目录和图谱就能跑,资料变多后再加 embedding,不必一上来就搭一套完整 RAG。
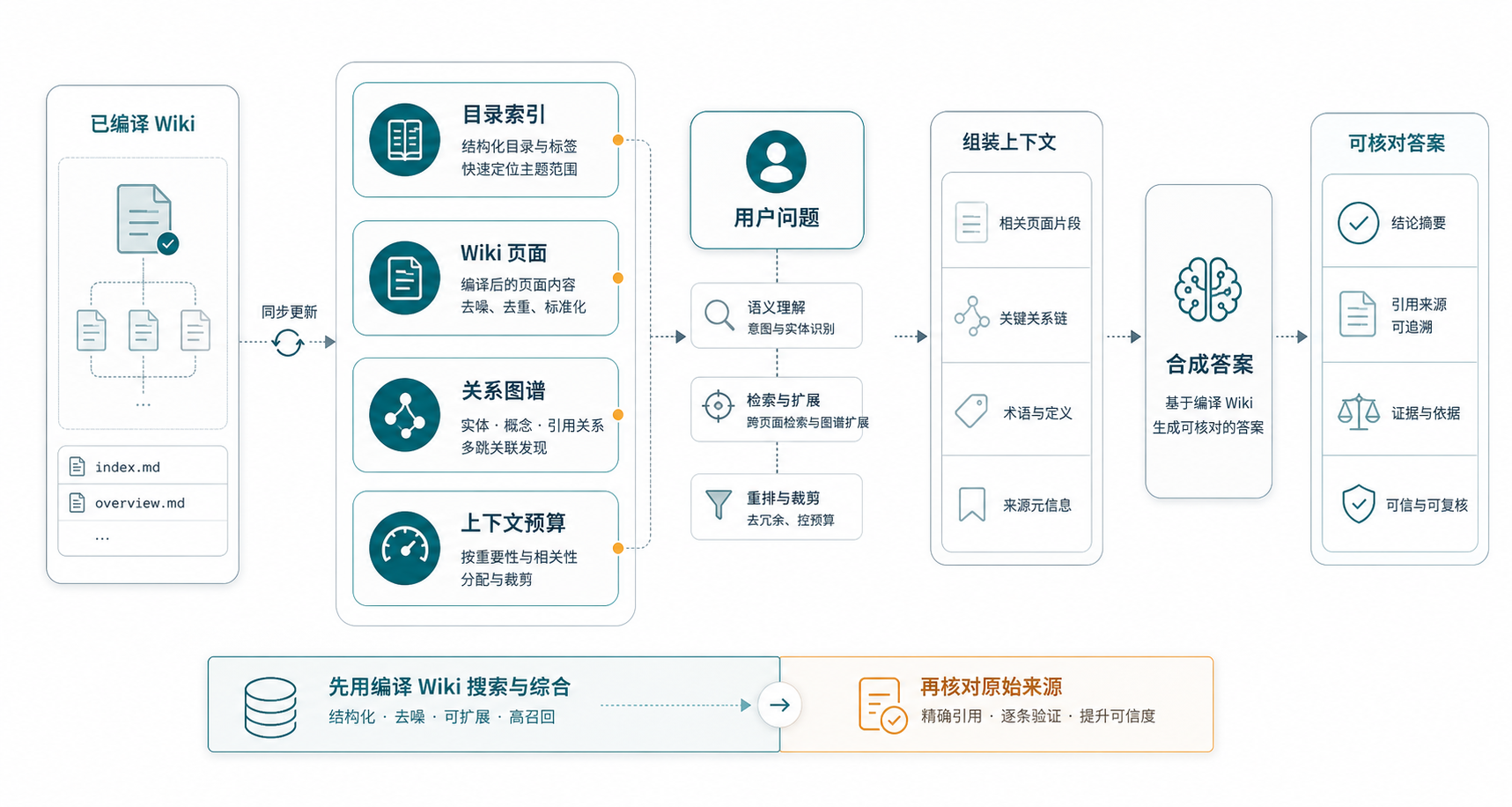
第四是能接 AI Agent。
它提供本地 HTTP API,运行在 127.0.0.1:19828,带 token 保护。外部工具可以列项目、读文件、做混合检索、访问图谱、触发源文件重扫。项目还提供了单独的 agent skill,可以装进 Claude Code / Codex。
这点很有用。个人知识库如果只能在一个应用里查,价值会被锁住;如果 Agent 写文章、做研究、改项目时也能查本地 Wiki,它就变成了一个长期上下文层。
怎么用更稳
它的基本用法不复杂。
先下载安装桌面应用,创建一个项目,选一个适合自己的模板。然后在 Settings 里配置 LLM provider 和模型。接着把资料放进 Sources:PDF、文档、Markdown、网页剪藏都可以。
导入后,看 Activity Panel 的处理状态。LLM 会把资料拆成 Wiki 页面,更新目录和总览。后面可以在 Chat 里提问,也可以去 Graph 看内容之间的关系,再到 Review 里处理需要人工判断的条目。
如果你已经用 Obsidian,也可以把生成的 Wiki 当成一个 vault 来看。Karpathy 原文里那种“Obsidian 看图谱,LLM 负责维护”的感觉,在这里被做成了更完整的应用流程。
更稳的试法,是先拿一个边界清楚的小主题。
比如:
- 一组读书笔记。
- 一个产品调研。
- 一套项目文档。
- 一个长期学习主题。
不要一开始就把所有收藏都倒进去。资料越杂,越需要先定义 purpose.md:这个知识库要回答什么问题,不收什么内容,哪些判断必须人工确认。
它不是万能收藏箱
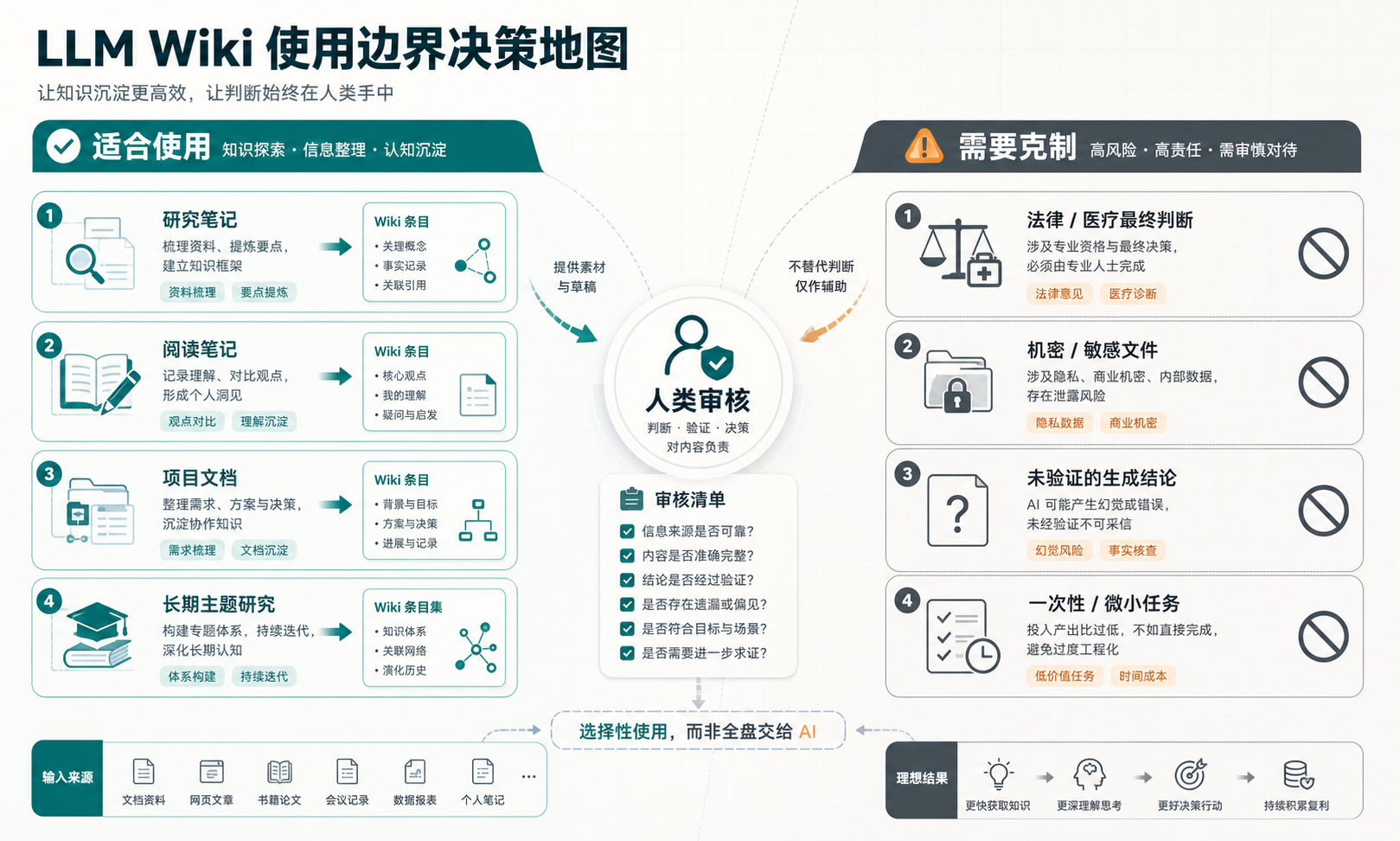
LLM Wiki 适合解决“收藏越多越乱”的问题,但它不是把所有资料自动变成真理的机器。
法律、医疗、财务、商业机密这类内容,不能把生成结论当最终答案。它更适合帮你整理材料、暴露关系、提示矛盾和待审核项。最后该信什么,还是要人决定。
它也不一定适合一次性小任务。如果只是总结一篇文章,聊天窗口就够了。LLM Wiki 的优势在长期:资料会不断增加,以后还会回头查,而且查的时候需要知道来处。
Karpathy 给的是一个很漂亮的理论骨架:让 LLM 维护 Wiki,让知识持续复利。nashsu/llm_wiki 做的是把这个骨架变成工具:有桌面界面,有导入队列,有图谱,有 Review,有 Web Clipper,有本地 API。
各种收藏越积越多时,真正缺的不是再多一个收藏夹,而是一套能持续整理、能回溯来源、还能让人审核的工作流。
这就是 LLM Wiki 值得试的地方。