选择器总失效?Scrapling 来补救
爬虫最麻烦的地方,经常不是第一版抓不到数据,而是过几天页面一改,选择器就开始空跑。
这种问题很烦。代码没大改,目标数据也还在页面上,只是 class 名、层级、旁边的结构换了。最后还是要人回去看页面、改选择器、重跑脚本。
D4Vinci/Scrapling 有意思的地方就在这里。它不是只给 Python 多包一层请求库,而是把静态请求、浏览器抓取、隐身抓取、spider 和 adaptive selector 放到一套框架里,试图把“网页变了之后怎么少返工”也纳入工具设计。
真正痛的是维护
很多爬虫项目一开始都很轻:一个请求,一个解析器,几行 CSS selector,数据就出来了。
麻烦通常从第二周开始。
页面结构变了,原来的 selector 找不到元素;列表页加了异步渲染,普通请求拿不到内容;网站多了访问限制,脚本开始不稳定。项目越往后,代码里就越容易堆出一堆补丁:这里 sleep 一下,那里换个 selector,再单独写一个浏览器版本。
Scrapling 的定位不是“更快地发请求”这么简单。它更像是把爬虫的几种常见状态收在一起:静态页面用轻的方式,动态页面用浏览器,需要更强伪装时再上更重的 fetcher。真正值得看的,是它没有把所有场景都推向最重的方案。

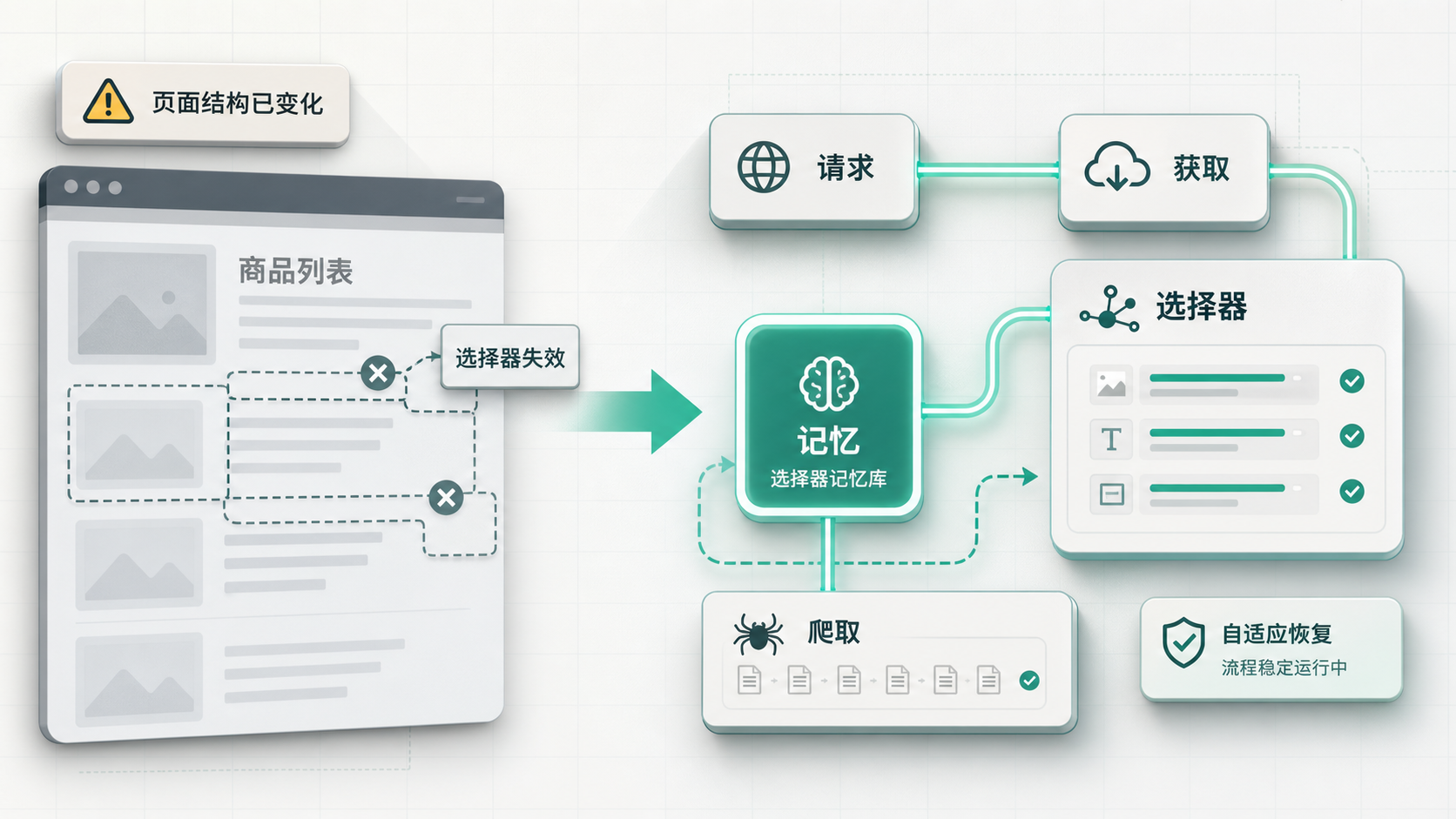
adaptive selector 是核心卖点
Scrapling 里最容易让人记住的是 adaptive scraping。
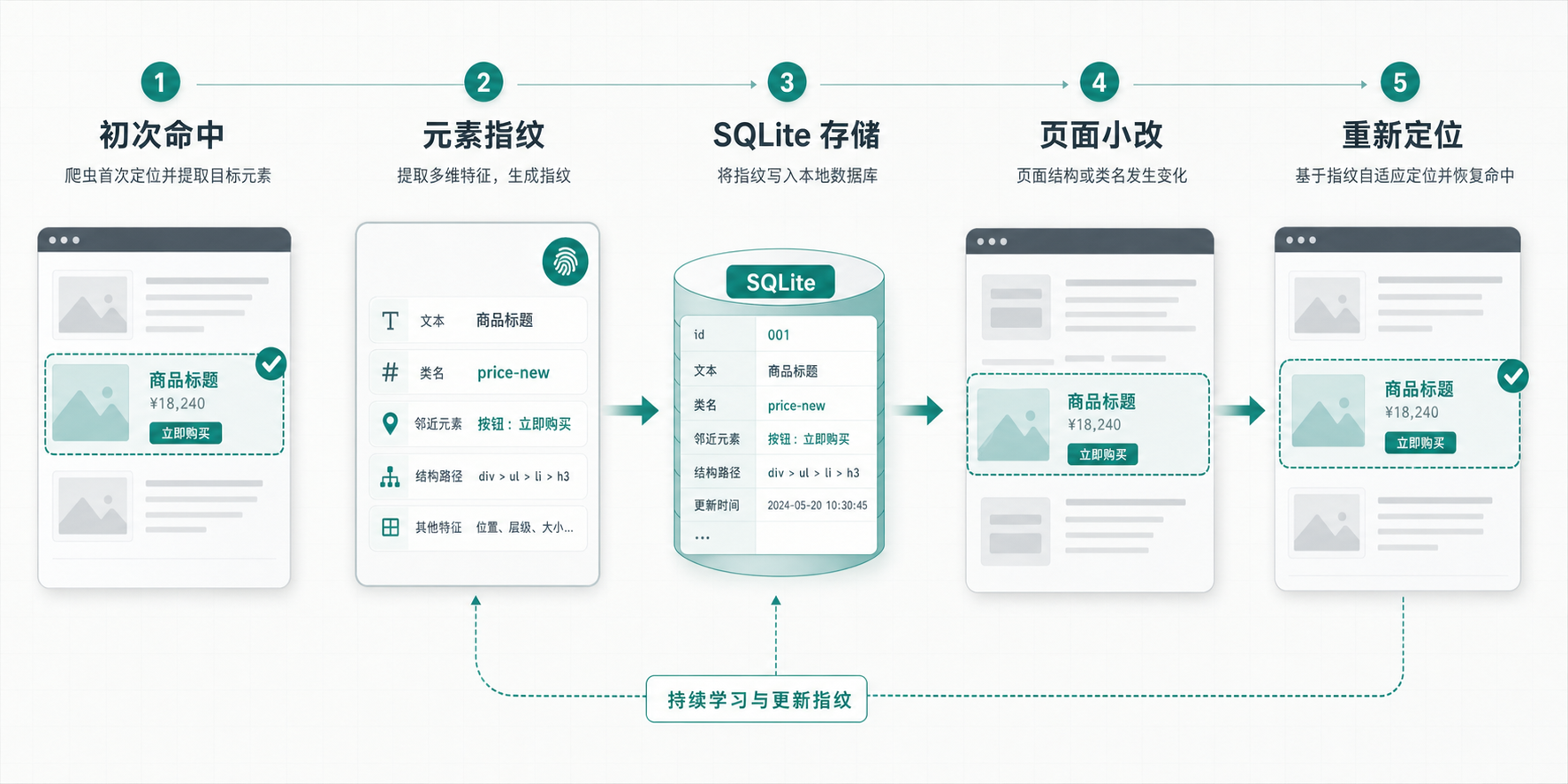
它的思路大概是:第一次找到某个元素时,把这个元素的一些特征存下来。后面页面结构变化、原来的 selector 不再命中时,框架尝试根据这些已保存的特征重新定位元素。
这不是魔法,也不是 AI 自动理解网页。更像给元素留一份“指纹”:文本、属性、附近结构、路径信息之类的线索。文档里提到,默认会用 SQLite 存这些元素信息,也可以换成自定义 storage。
这个设计很适合应对小幅页面改版。
比如商品页只是 class 名变了,标题、价格和周围结构还在,adaptive selector 就可能帮你少改一次代码。但如果页面彻底重构,或者同类元素非常多,它也不可能凭空知道你真正想要哪一个。文档里也提醒过一个限制:目前在 find_all 这类场景下,adaptive 保存的是第一个元素,这会影响批量元素的恢复效果。
所以它最适合的不是“完全没人维护的爬虫”,而是那些目标稳定、页面偶尔小改、选择器维护成本很烦的任务。
Fetcher 不该一上来就最重
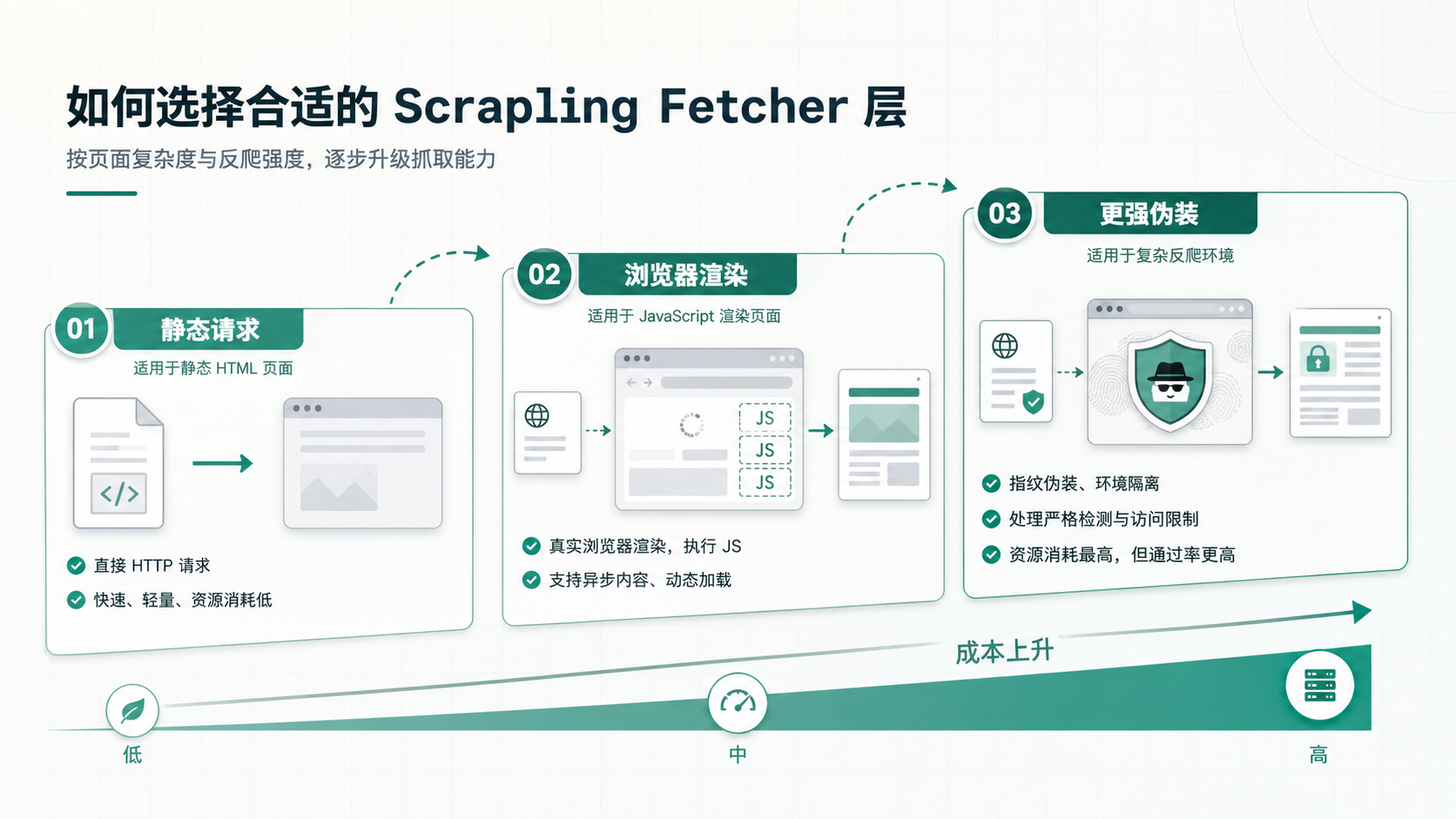
Scrapling 把抓取入口拆得比较清楚。
Fetcher 适合普通静态页面。能直接请求到 HTML,就不要先启动浏览器。这个判断很重要,因为很多爬虫一旦加上浏览器,资源消耗、运行速度和部署复杂度都会上一个台阶。
DynamicFetcher 面向需要 JavaScript 渲染的页面,底层会用到浏览器能力。它适合那些列表、价格或按钮状态必须等前端跑完才出现的页面。
StealthyFetcher 则更偏“反检测”场景。文档里把它放在更强伪装的位置,底层实现也随版本调整过。这类能力有用,但也更容易让人误用。它解决的是技术上的可达性,不代表你就应该抓。
这三个层级放在一起,Scrapling 的取舍就比较清楚:先用便宜的方式,必要时再升档。这个思路比“一上来全站浏览器自动化”要健康很多。
Spider 层解决的是秩序
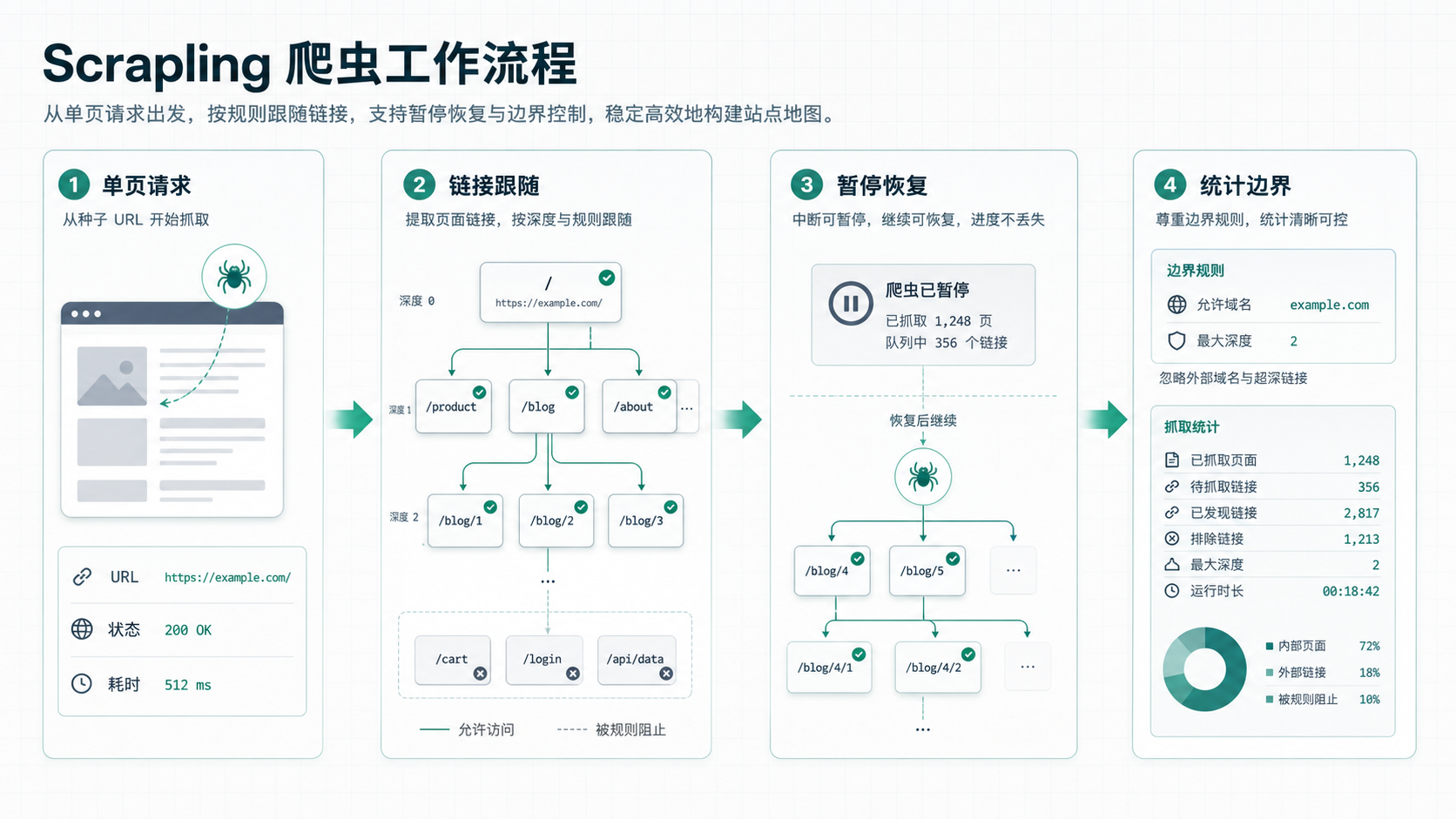
单页抓取和整站爬取不是一回事。
Scrapling 也提供 spider。它的写法有点接近 Scrapy:定义 start_urls,写 parse,再把结果和后续链接交给框架处理。文档里还提到统计、暂停、恢复、域名限制、链接跟随深度这些能力。
这些东西看起来不如 adaptive selector 新鲜,但长期项目里很重要。
爬虫一旦从“抓一个页面”变成“持续跑一批页面”,就需要秩序。哪些域名能抓,失败怎么处理,跑到哪里可以暂停,继续跑时怎么恢复,都是实际会遇到的问题。没有这层,脚本很容易变成一次性工具。
Scrapling 的 spider 层更适合那些还没大到需要完整分布式爬虫,但已经不想再维护零散脚本的场景。
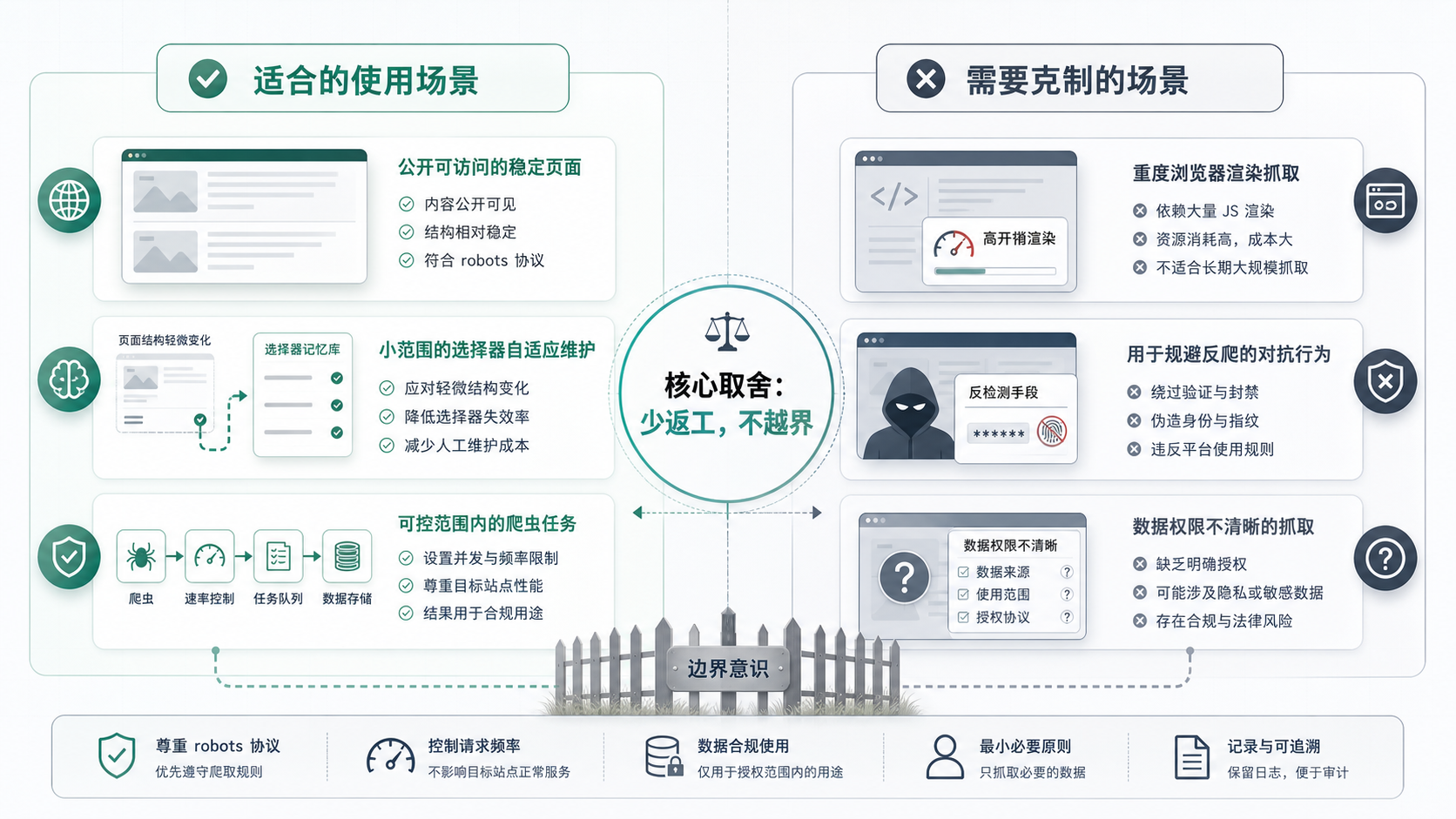
边界要自己守住
Scrapling 也有很明确的边界。
第一,adaptive selector 只是提高恢复概率,不是保证页面怎么变都能抓。页面语义变了、同类元素太多、目标内容本身消失,它都可能失败。
第二,浏览器抓取和隐身抓取会提高复杂度。依赖、浏览器安装、运行资源、部署环境,都会比普通请求麻烦。只有当页面确实需要 JavaScript 或访问环境更复杂时,才值得用。
第三,反检测能力不是通行证。文档里有 robots_txt_obey 这类配置,并且提到启用后会遵守 Crawl-delay 和 Request-rate。这类配置不该只是“可选项”,而应该成为真实项目的默认检查。
爬虫工具越强,越需要把边界写清楚。公开页面、合理频率、必要范围,这些判断不能交给框架替你做。
适合怎么试
如果只是好奇,没必要一上来就拿复杂网站测试。
更稳的试法是找一个公开、结构稳定、访问压力很低的小页面,先用 Fetcher 跑通普通请求,再挑一个容易变化的元素试 adaptive。确认能读、能存、能在 selector 变化后恢复,再考虑 DynamicFetcher 或 spider。
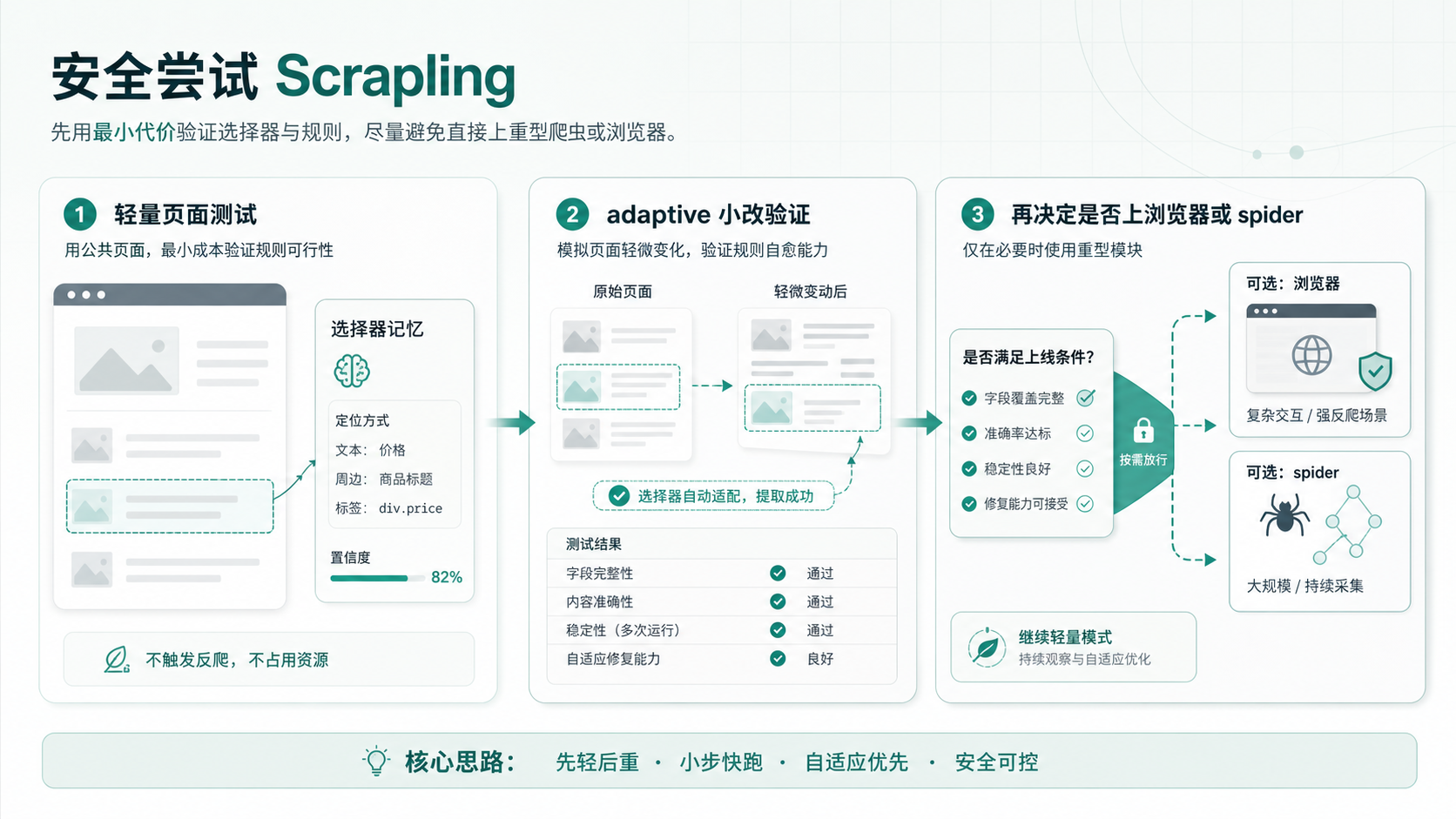
如果项目已经需要长期维护,再去看这些问题:
- 目标页面是静态还是必须跑 JavaScript。
- selector 失效是不是经常发生。
- 是否需要暂停、恢复、统计和域名限制。
- 抓取范围是否符合网站规则和自己的使用边界。
Scrapling 最值得关注的,不是“一个框架能处理从单个请求到全面爬取的一切操作”这句口号,而是它把爬虫后期维护里最烦的几件事放在了台面上。
前面写 OpenWolf 时聊过一个类似方向:工具不一定要变得更激进,有时只是让系统少重复犯错。Scrapling 放在爬虫领域,也是这个味道。