Open-LLM-VTuber:别让 AI 困在聊天框
想让 AI 像个桌面伙伴,最容易卡在聊天框里。
打字、等待、读回复,再打字。模型再聪明,也像隔着一层表单。它听不到你说话,看不到屏幕变化,也不会用表情和声音回应你。很多人想要的“AI 伙伴”,其实是少一点打字、少一点等待,多一点自然来回。
Open-LLM-VTuber 抓住的就是这件事。它把实时语音对话、视觉感知、LLM、TTS 和 Live2D 角色接在一起,让 AI 不只停在一个聊天窗口里。项目当前约 1 万 star,支持 Windows、macOS 和 Linux,也提供 Web 版本和桌面客户端。它想做的是把 AI 放到桌面上,让它能听、能说、能看,也能以角色形象回应你。

只看 Live2D 角色,Open-LLM-VTuber 很容易被误解成“套了个皮套的聊天机器人”。但这个项目真正麻烦、也真正有意思的地方,在于它要把一整条实时交互链路接起来。
你说话,ASR 要先把声音转成文本;LLM 负责理解和生成回复;TTS 再把回复变成声音;角色要根据情绪、文本或后端指令做表情;如果打开视觉感知,它还要处理摄像头、屏幕录制或截图。每一环都能换模块,也都可能带来延迟、配置和硬件要求。
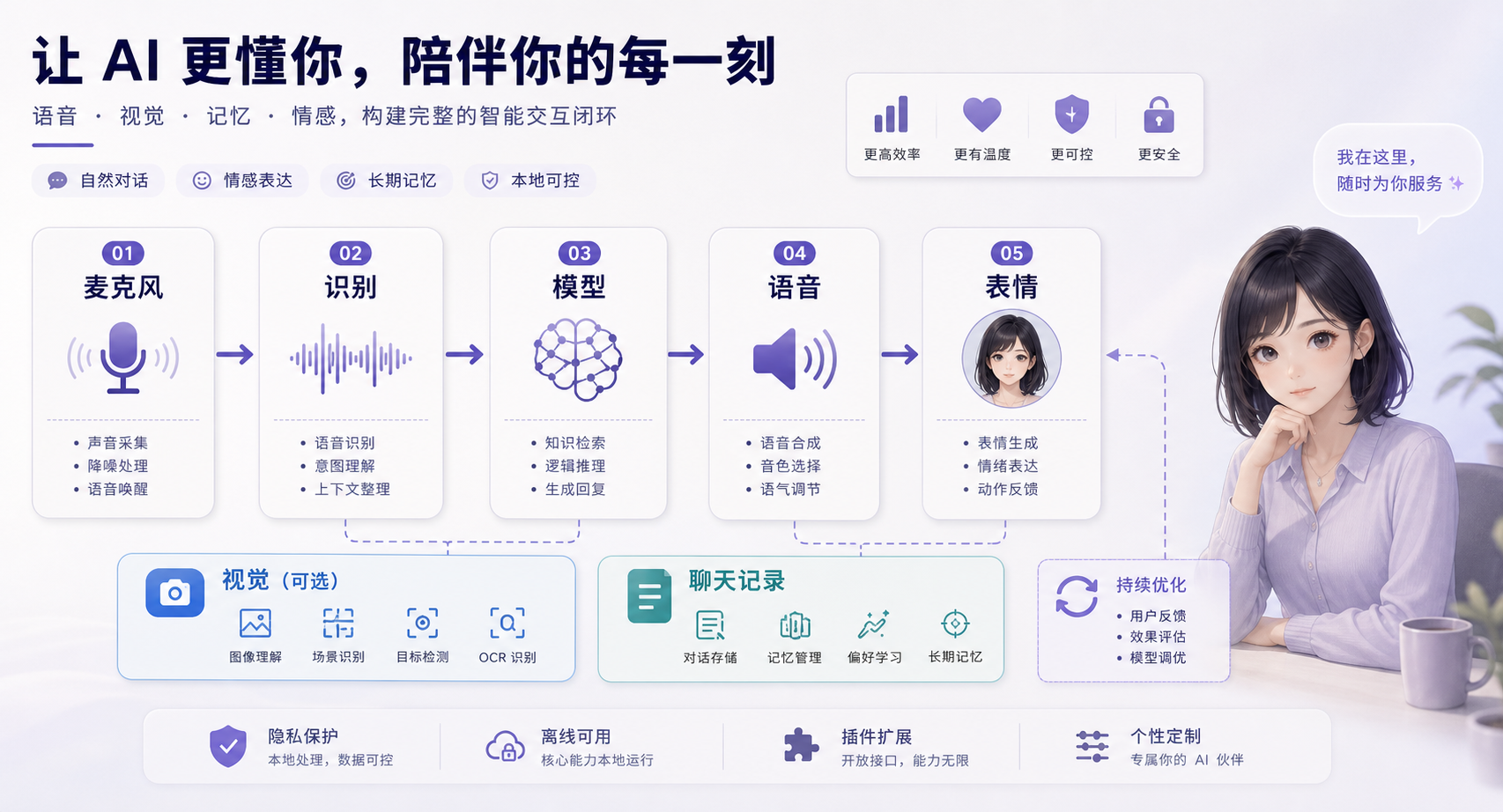
项目资料里列了不少支持项:LLM 可以接 Ollama、OpenAI 兼容 API、Gemini、Claude、Mistral、DeepSeek、LM Studio、vLLM 等;ASR 覆盖 sherpa-onnx、FunASR、Faster-Whisper、Whisper.cpp、Groq Whisper、Azure ASR;TTS 也能接 sherpa-onnx、pyttsx3、MeloTTS、GPT-SoVITS、Bark、CosyVoice、Edge TTS 等。这些名字不用背,重要的是它没有把你锁死在某个模型或云服务上。
它也强调可以完全离线运行。对想做本地 AI 伙伴的人,这个点很关键。语音、聊天记录、屏幕内容和摄像头画面都很敏感,如果每一步都要外发到云端,很多场景根本不敢用。本地模型当然会带来性能压力,但至少给了一个可控选项:想省事就接云 API,想把数据留在机器里,就用本地模型慢慢调。
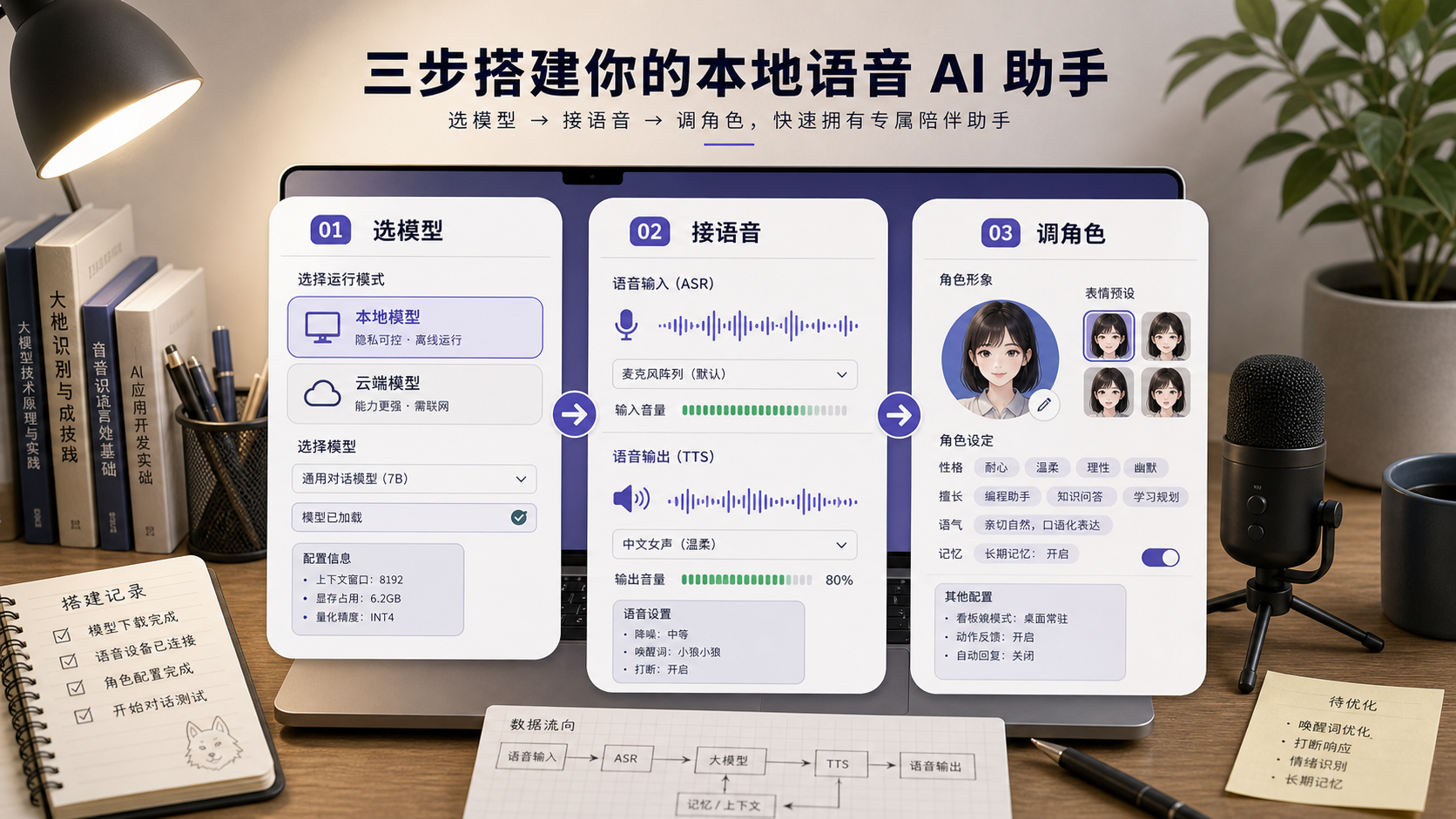
不过它不是那种“下载就能无脑用”的轻工具。
Open-LLM-VTuber 当前仍处在活跃开发阶段,仓库里也说明 v2.0 正在讨论和规划,v1 继续修 bug、处理现有 PR。版本变化本身就意味着要留意配置兼容。项目还提醒过,如果远程跑服务、想在另一台机器或手机上访问页面,需要配置 HTTPS,因为浏览器前端的麦克风只能在安全上下文里启动。这个细节很现实:你以为自己在搭 AI 伙伴,结果第一步卡在浏览器权限。
还有 Live2D 模型授权。仓库里包含的示例模型由 Live2D Inc. 提供,项目说明这些素材有单独授权,尤其商业使用要额外确认。个人折腾没什么问题,但如果想做直播、商用展示或产品化,角色素材不能随手拿来就用。
这也是它的适用边界。
如果你只是想要一个轻量聊天工具,或者电脑配置一般、不想折腾模型、语音、依赖和角色设置,Open-LLM-VTuber 可能会显得太重。它更适合愿意把 AI 当成桌面长期伙伴来调的人:希望它能常驻屏幕,能语音打断,能看屏幕或摄像头,能用角色形象给出反馈。这个方向的吸引力不在“回复更聪明”,而在交互方式终于不像填表。
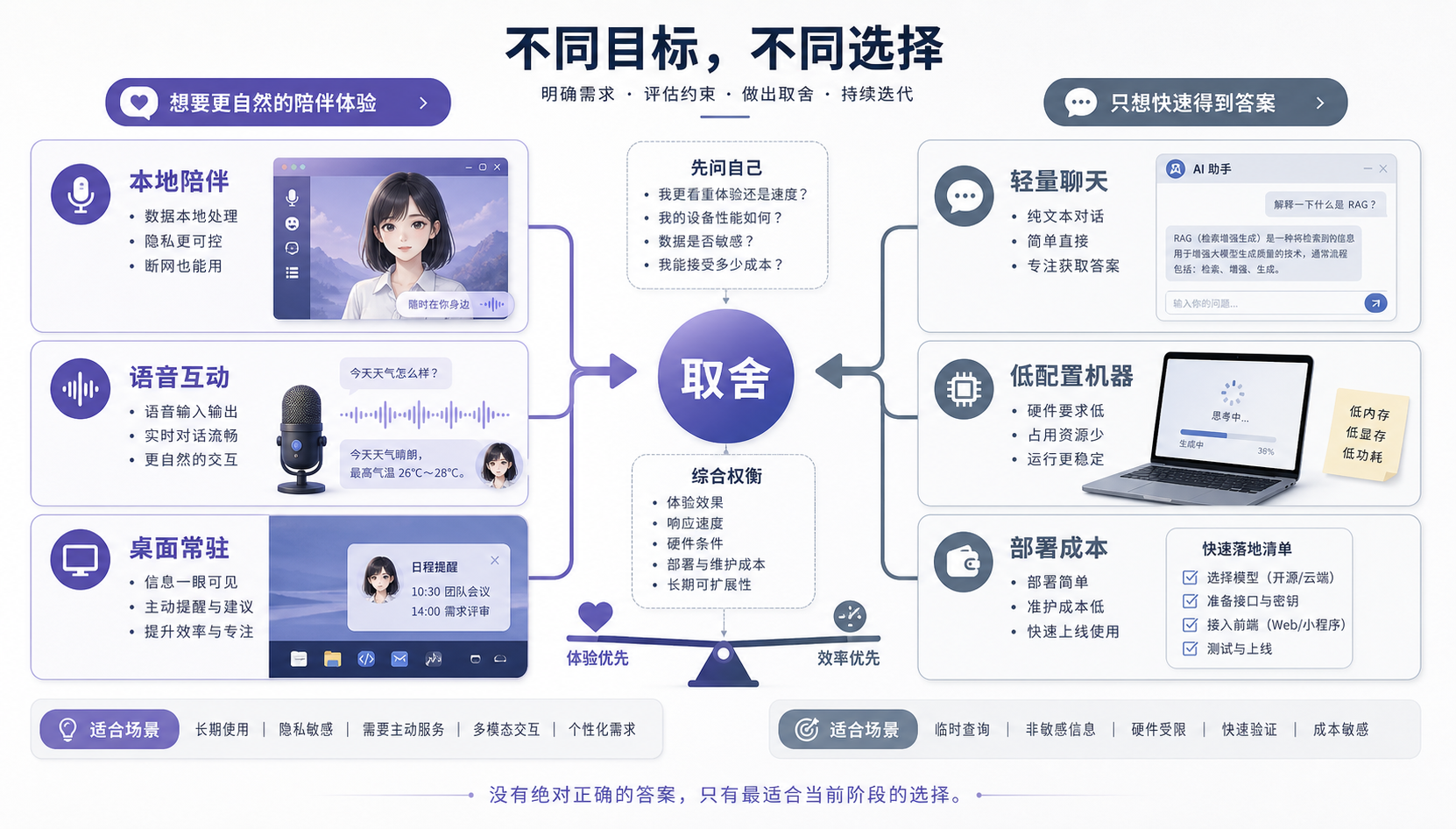
真正要试它,建议先收窄目标。
先别急着把所有模块都接满。第一步只跑通一个模型和基础文字对话;第二步接上麦克风和 TTS,观察延迟能不能接受;第三步再去调角色、表情、视觉感知和桌面常驻。只要一开始就追求“全功能 AI 伙伴”,很容易被依赖、模型下载、声音配置和浏览器权限拖住。
Open-LLM-VTuber 让人感兴趣的地方,在于它把聊天框以外的交互成本摊开了。语音、视觉、角色、记忆、屏幕常驻,这些东西单独看都不新,但接到一起之后,AI 才开始从“问答工具”变成“桌面上的一个存在”。
这条路还会有很多粗糙的地方。可如果 AI 以后真的要进入日常工作和陪伴场景,它迟早要从聊天框里走出来。
后面会继续写 AI Companion、语音交互、桌面 Agent 和本地模型工具。重点不追炫技,而是看它们能不能真的进入日常工作流。