Headroom:别让上下文偷烧钱
AI Agent 用久了,会发现 token 不是只花在聊天上。
更常见的情况是,工具返回一大段日志,搜索结果塞进几十条,RAG 把相似片段全捞上来,代码助手又把文件、diff、历史记录一起丢进窗口。模型看起来在认真读项目,实际有一半精力花在噪音里翻东西。
Headroom 看的就是这个入口。它把日志、工具输出、文件、RAG chunk 和对话历史先处理一遍,再送进 LLM。项目给出的目标是减少 60% 到 95% token,同时尽量保住回答质量。这个数字当然要放到自己的工作流里验证,但思路很直接:先把进模型的东西收拾干净。
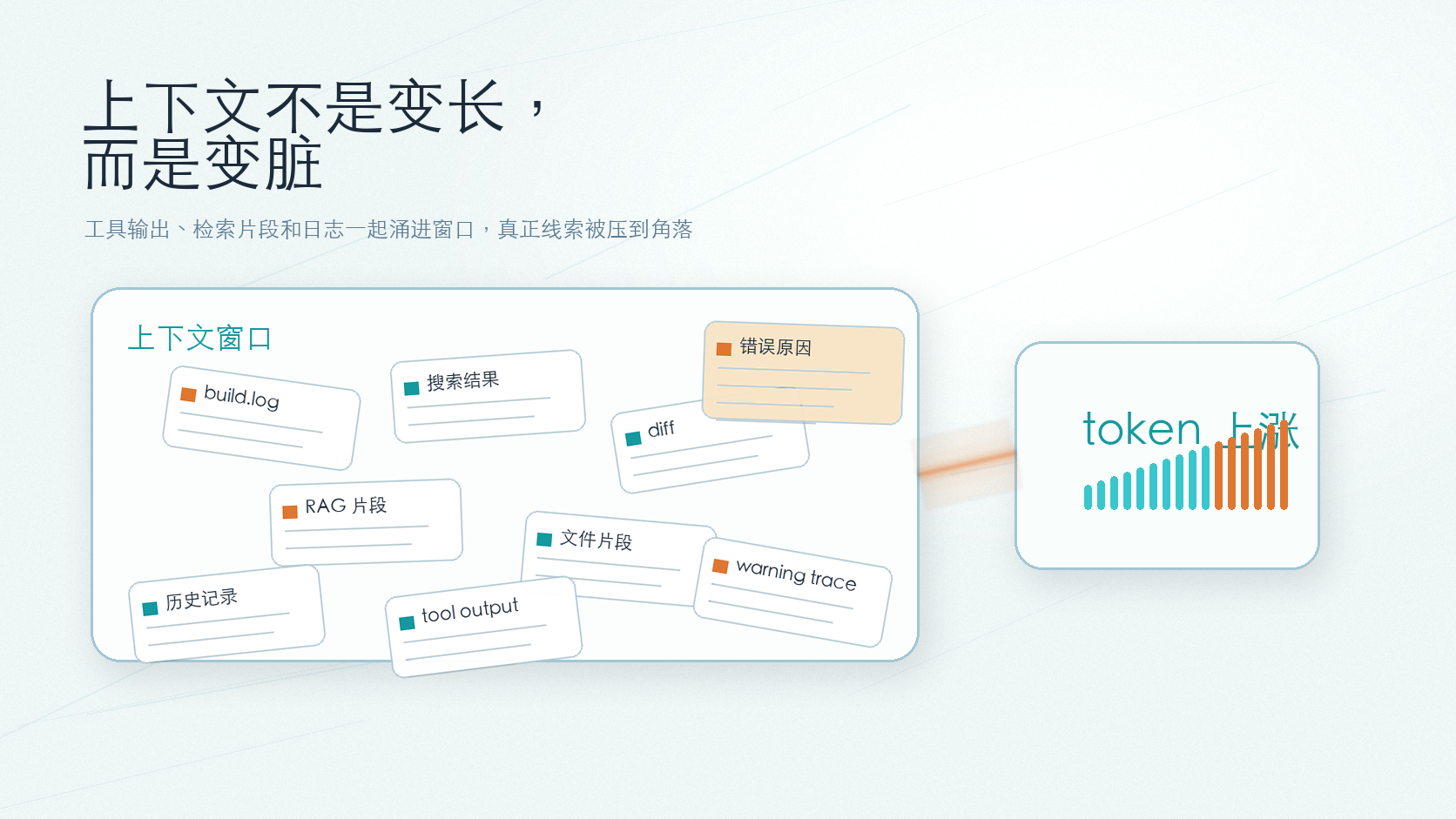
上下文压缩最怕粗暴截断。少了几千 token,看起来省钱了;但如果刚好删掉报错行、文件路径或者引用片段,后面排查问题会更麻烦。
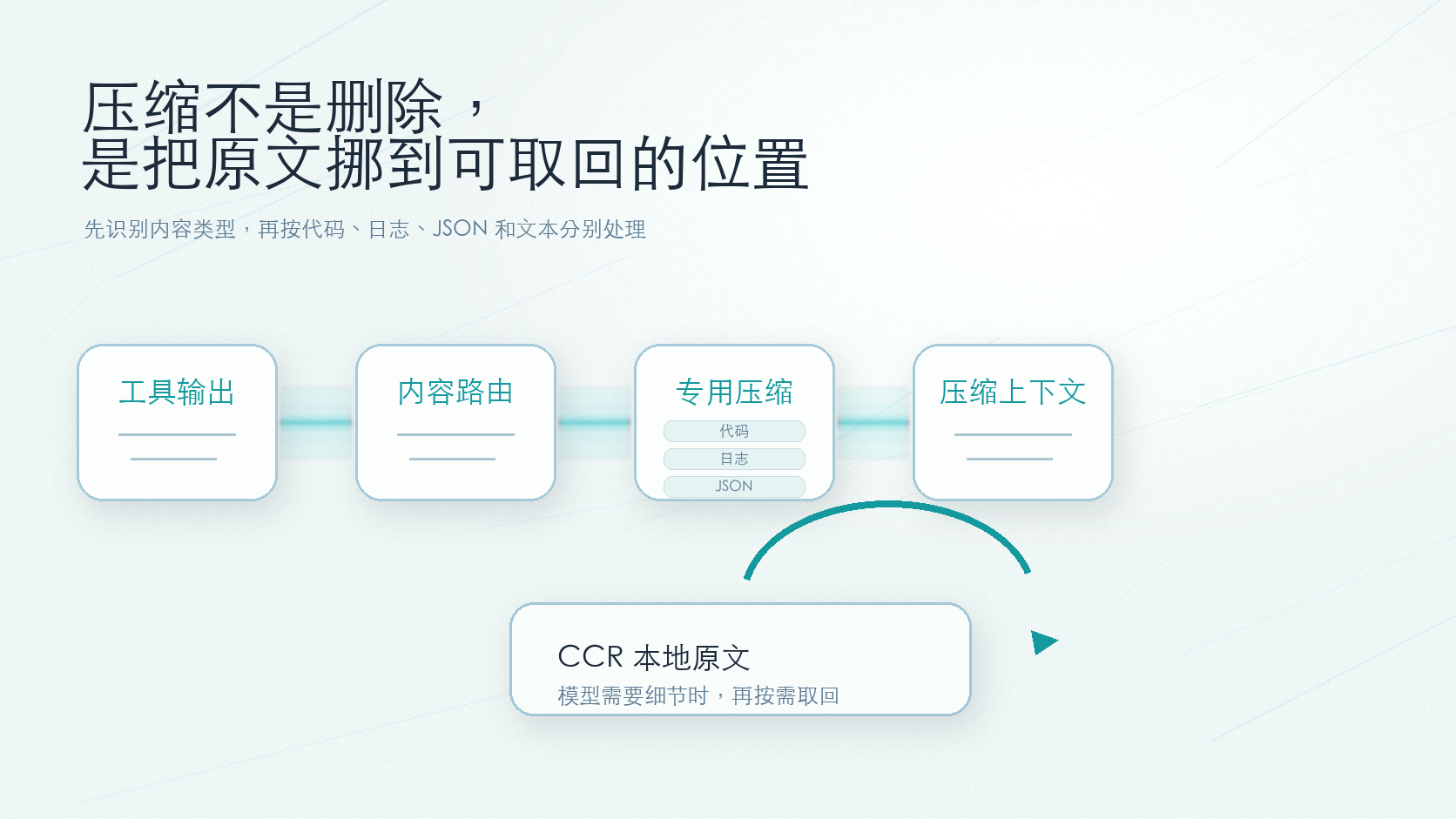
Headroom 的处理方式更接近“先分类,再压缩”。JSON、代码、日志、普通文本会走不同策略,不会统一压成几句摘要。这个细节对代码 Agent 很重要。日志里关键的可能只有一行错误;代码搜索结果要保住符号、路径和匹配片段;RAG 结果还得留住引用关系。把这些东西压扁成一段话,模型读起来轻松了,证据也可能没了。
它留了一个回头路。CCR 会把原文放在本地,压缩后的内容先进模型;如果后面需要细节,可以再通过 headroom_retrieve 把原始内容取回来。也就是说,它不是把信息删掉,而是把原文从模型窗口里挪到一个可检索的位置。
几个公开示例能看出它针对的不是普通问答。代码搜索从 17,765 tokens 压到 1,408;SRE 事故排查从 65,694 压到 5,118,两项都标了 92% 节省。这里不能简单理解成每个人接上就能省这么多,但它说明 Headroom 的主场很明确:工具输出多、上下文很脏、模型每次都被迫读一堆边角料。
接入方式没有绑死在一种姿势上。愿意改代码,可以在 Python 或 TypeScript 里直接调用;不想动业务逻辑,可以让请求先走本地 proxy;用 MCP 的话,有 headroom_compress、headroom_retrieve、headroom_stats 这些工具;常见代码 Agent 也能通过 wrapper 接进去,包括 Claude Code、Codex、Cursor、Aider 和 Copilot CLI 这类工具链。

这类工具最适合的人,不是偶尔问两句 AI 的用户,而是每天让 Agent 读项目、跑命令、查日志、扫文档的人。
比如排查构建错误,终端一次吐出几百行;让 Agent 读仓库,搜索结果和文件片段不断堆进窗口;让知识库回答问题,RAG 片段越捞越多。普通做法是等上下文不够了再补救,Headroom 更像在入口加一层过滤器,让没必要的信息少一点进入模型。
还有一个功能值得单独提一下:headroom learn。它会从失败会话里找常见错误和修正,把经验写进 CLAUDE.md、AGENTS.md 这类 Agent 规则文件。这个方向和单次压缩不一样,更像是把踩坑沉淀成项目记忆。团队里如果同时用多个 Agent,共享这种经验会比每个工具各自长记性更省事。

但也别把它当成必装插件。
如果只是普通问答,或者只用模型自带的上下文能力,Headroom 未必能带来明显收益。它需要本地进程、proxy 或 MCP 配合,环境太受限时也不好部署。另一个要留意的是 telemetry:当前公开说明里写到默认开启,认真接入前应该先看清配置项,必要时关掉。
Headroom 可以放进待试列表,因为它把“上下文成本”从模型内部挪到了工程入口。以前很多人把 token 浪费当成模型使用成本的一部分,等窗口撑不住了再补救;它的判断更工程化:工具输出、日志、文件和检索片段本来就应该先整理,再进入模型。
不是每个项目都需要这一层。但只要工作流开始频繁读文件、跑命令、查日志、接 RAG,上下文就不该继续裸奔。
后面会继续写上下文工程、MCP、代码助手和知识库工具。重点不追热榜本身,而是看它们能不能帮真实工作少一点浪费。