AI 学习,别只囤课
最近看 AI 学习资料,最大的感受不是不够学,而是太容易学散。
今天补一点 attention,明天试一下 RAG,后天又去折腾 agent 和 MCP。每一块单看都挺有用,也都能很快做出一点东西,但这些东西常常接不起来。到最后,手里有一堆笔记、一堆链接、几个能跑的 demo,真要回头讲清楚一条链路,反而会卡住。

所以我看到 rohitg00/ai-engineering-from-scratch 这类仓库时,第一反应已经不是“又来一份学习路线图”,而是想看看它到底有没有把这些断开的地方接上。

翻完 README 之后,我会把它留下来。原因很简单,它不是只在劝人“先打基础”,而是真的把基础、工程和最后能交付出去的东西放进了同一条路里。
仓库公开写得很清楚:整套内容分成 20 个阶段,473 节课,估算总时长大约 320 小时。前面从数学、机器学习、深度学习往上走,后面再进入 transformer、LLM、multimodal、tools、MCP、agent engineering 这些现在更常被拿来直接做项目的部分。
这个顺序我挺认同。现在很多人其实是反着学 AI 的,先学最容易见效的那层。怎么接 API,怎么写 prompt,怎么让 agent 调工具,怎么把一个 demo 跑出来。这种走法也没问题,毕竟先跑起来本来就重要。但问题是,只要再往里走一点,就会发现底下那层空着。效果为什么不稳定,不知道。结构为什么这样搭,也说不清。换个场景以后还能不能迁过去,更没底。
这也是我愿意多看一眼这套东西的原因。它没有把“基础”写成一段正确但没用的废话,而是继续往后接,接到现在大家真正会碰到的工程问题上。
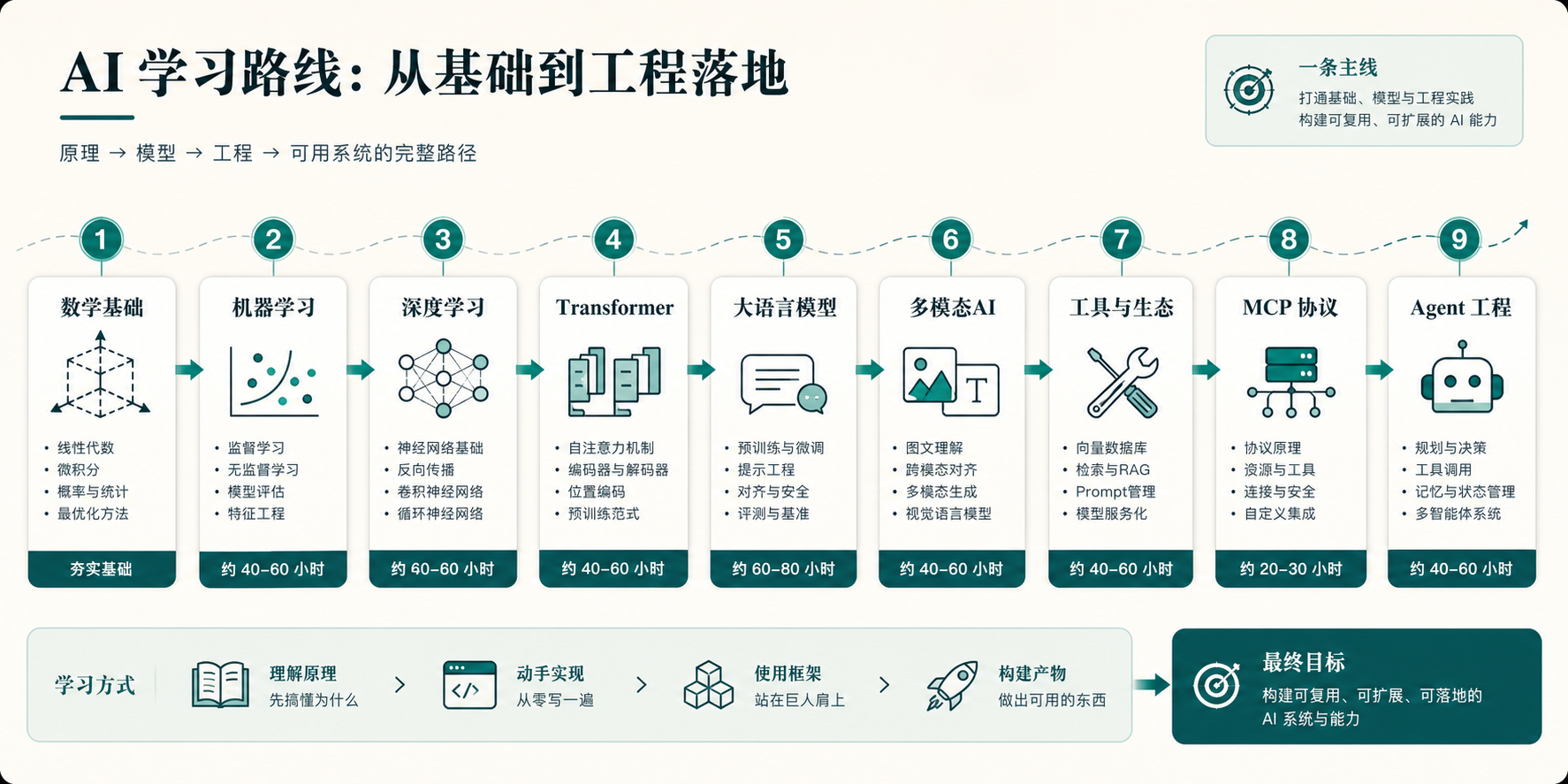
README 里还有一个细节,我印象挺深。它不是把每节课都做成“读完概念就结束”的那种材料,而是明确写了 Build It, Use It, Ship It。也就是说,前面学原理,后面要自己写代码,再往后要去用框架,最后还得留下一点能继续带走的东西。
这点很关键。因为真正让人学会的,很多时候不是“看懂了”,而是“做完以后还剩下什么”。
如果一节课结束,只多了一页笔记,那下次很可能还得从头翻。如果最后能留下一个 prompt、一段 skill、一个 agent,甚至一个 MCP server,事情就不一样了。它和工作流接上了,和日常使用的工具也接上了。下次再碰到类似问题,不是重新学,而是从已有东西继续改。
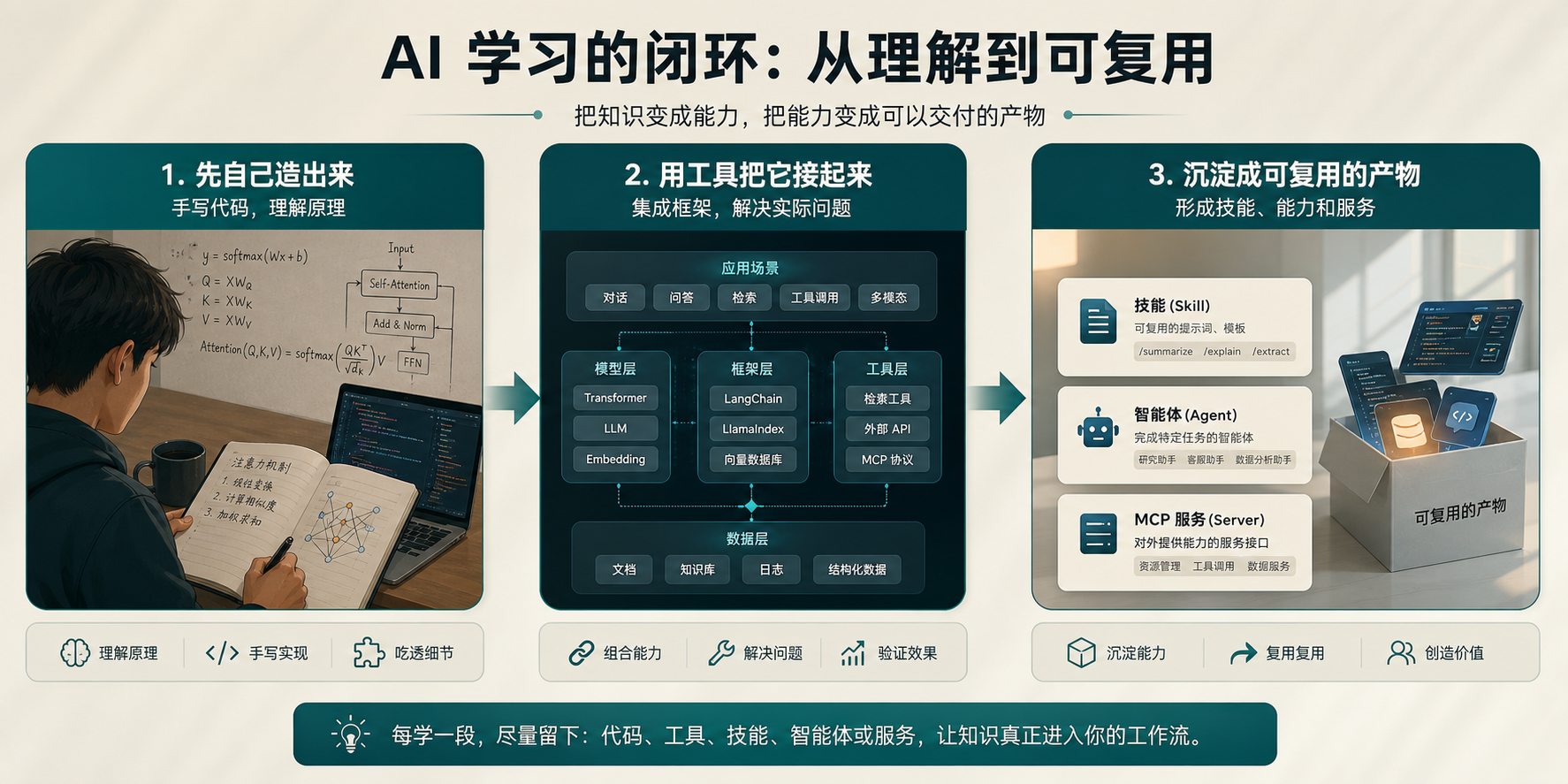
我前面写 CodeGraph、OpenWolf 和 Agent 不缺了,缺的是怎么装 的时候,其实都在看同一类问题:怎么把原本很散的东西收回来。有人收上下文,有人收记忆,有人收能力分发。这个仓库收的是学习路径本身,而且它想收的,不只是目录,而是“学完之后能留下什么”。
如果你已经在折腾 agent、RAG、MCP,这套内容后半段反而更值得看。README 里把后面的路线列得很直白,Phase 13 是 Tools & Protocols,Phase 14 是 Agent Engineering,再往后还有 Autonomous Systems 和 Multi-Agent & Swarms。它显然不只是给纯入门用户准备的。
另一个挺实在的设计,是仓库里放了 /find-your-level 和 /check-understanding 这类 agent skill。这个点我挺喜欢,因为大多数人不是完全不会,而是卡在“不知道该从哪补”。明明已经能做东西,但一到某个环节就开始发虚,又说不清到底是 transformer 没补够,还是 LLM engineering 没摸明白,还是 tools 这一层还没吃透。
有这种分层定位工具,比一上来劝人“从第一章开始重学”要实在得多。
当然,这个仓库也有一个很现实的问题:体量不小。20 个阶段、473 节课、约 320 小时,怎么看都不是那种周末刷完就能结束的清单。再加上它强调先手写、再上框架,前面那段路大概率不会轻松。
所以我现在更愿意把它当成主骨架,而不是打卡表。
真要照着学,我不会建议从头机械往后推。更像是先拿它判断自己现在站在哪,再决定是回去补底层,还是直接啃 tools 和 agent 那几段。这样更接近真实学习状态。毕竟多数人不是从零开始,也不是每个人都缺同一块。
说到底,我现在对“AI 学习资料”的期待已经变了。不是谁整理得更全,也不是谁列的关键词更多,而是谁能让人别越学越碎。
ai-engineering-from-scratch 至少给了一种靠谱一点的收法:别把基础和应用拆成两张互不相干的清单,也别把工程实践学成一次性 demo。每学一段,最后都尽量落回代码、工具和可以继续复用的产物里。
这条线如果真能走通,价值会比再囤十个课程链接大得多。
项目地址: